AI News – Claude Opus 4.5 Detailed Benchmark


Claude 4.5 Opus vs Gemini 3 Pro: Benchmarks, Pricing per Solution, and the Week’s Biggest AI Moves
Estimated reading time: 11 minutes
Key takeaways
- Execution vs. reasoning: Claude 4.5 Opus is the surgical executor for code and tool chains, while Gemini 3 Pro (and GPT‑5.1) often win on big‑picture reasoning.
- Price per solution matters more than sticker price: measure token efficiency, retries, and latency to compute true cost, see Anthropic pricing, Vertex AI pricing, and OpenAI API pricing for list rates.
- Policy accelerates pace: the Mission Genesis initiative signals faster public‑sector push and tighter procurement rhythms.
- Jobs effect is near‑term: automation models from MIT and McKinsey show substantial upside for tasks that are well‑specified-plan pilots and governance now (MIT, McKinsey MGI).
Introduction
If you’re choosing between Claude 4.5 Opus and Gemini 3 Pro right now, the stakes are real.
Claude 4.5 Opus is the best executor on code and tools, while Gemini 3 Pro (and GPT‑5.1) often win on broad reasoning.
“Price per solution” beats sticker price-token efficiency and retries swing the total bill.
Below: fast takeaways followed by deeper sections on benchmarks, personas, pricing math, policy, product updates, and a practical buyer’s checklist.
Claude 4.5 Opus vs Gemini 3 Pro benchmarks (what the numbers really say)
Coding and execution
The Anthropic SWE‑bench leaderboard shows Claude 4.5 Opus with a strong SWE‑bench score (~80.9%), an indicator that Opus reads repos, makes changes, and lands fixes more reliably than peers.
Anthropic also cites internal tests where Opus matched or beat human engineer baselines. See the Claude 4.5 announcement for details.
On agentic tool use, chaining API calls, parsing errors, and retrying smartly, Opus generally edges Gemini 3 Pro. These effects show up in terminal/coding settings and in SWE‑bench variants hosted on GitHub.
Reasoning and knowledge tests
For broad cross‑domain reasoning, Gemini 3 Pro and GPT‑5.1 tend to sit at the top across suites like GPQA Diamond, MMMU/MMU, and MMLU.
These benchmarks reward long‑horizon planning and synthesis rather than line‑by‑line execution.
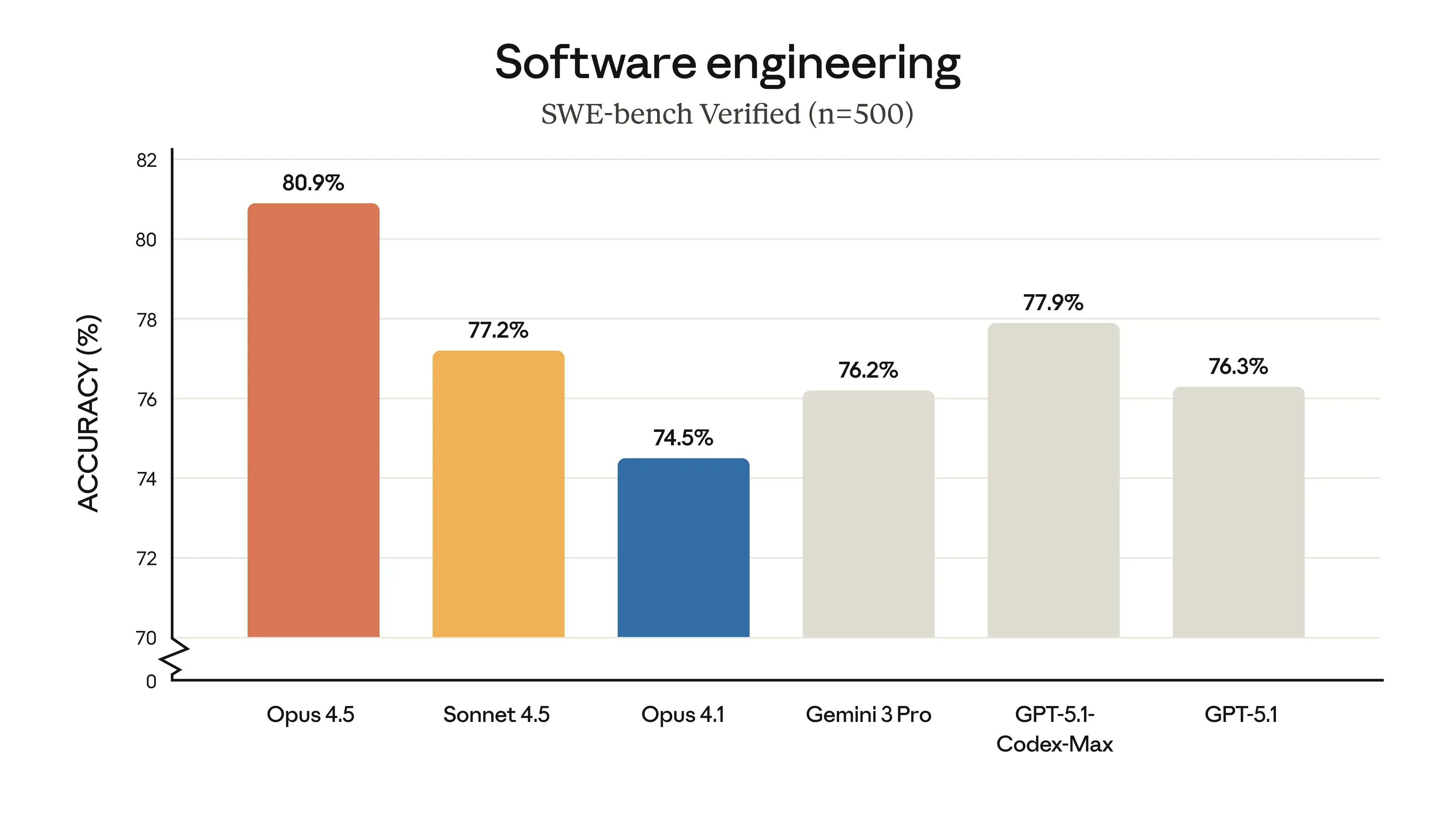
How to read the charts
“Watch for y‑axis tricks.” Many visualizations zoom on narrow bands (e.g., 75%–85%), making small gaps look huge. Replot zero‑based to get a clearer sense.
Practical takeaway
- Choose Opus for surgical execution, automated code fixes, and tool‑chain reliability.
- Choose Gemini 3 Pro / GPT‑5.1 when you need multi‑domain reasoning, consumer chat, or ideation at scale.
Model personas shaped by post‑training
Diverging optimization paths
Anthropic trains Opus to act like a careful, steady‑handed enginee-explaining steps, following constraints, and avoiding risky leaps. This approach is grounded in techniques like Constitutional AI.
Google and OpenAI tune toward wide‑angle reasoning: planning across domains and recovering from messier paths.
Market fit & implications
Expect product teams to mix models: a surgical executor for code and agents, and a wide‑angle planner for research and consumer flows.
Pricing that actually maps to value (AI model pricing per solution and token efficiency)
Sticker prices
Per‑million‑token rates are seductive but misleading. Current public pages list Gemini 3 Pro around $2 input / $12 output per million tokens (under large‑context caps), while Claude 4.5 Opus lists ~$25 per million output tokens. OpenAI sits in a similar flagship tier-always check the vendor pages before buying.
Token efficiency example
Anthropic reports Sonnet 4.5 using ~22k tokens vs Opus 4.5 at ~6k tokens for a SWE‑bench target (≈76% reduction). Fewer tokens and fewer retries can make a higher per‑token model cheaper per solved task-especially when you avoid human rework. (See the Claude 4.5 writeup.)
How to compare for your use case
- Pick 5–10 real tasks (code fix, 10‑page summary, multi‑step reply, spreadsheet→SQL).
- Run them on both models and log input/output tokens, first‑try success, retries, and time to done.
- Compute total cost per solved task, adding human time and rework.
Release pacing and the scaling story
Scaling laws and data/compute tradeoffs still matter. See classic work on scaling laws and subsequent analysis of data/compute tradeoffs (related paper).
Anthropic tends to time Sonnet and Opus drops near major Google/OpenAI moments-strategic pacing that keeps pressure on rivals while avoiding rushed releases.
Plan for 8–12 week minor‑version rhythms and keep your tests locked so you measure true progress.
Policy watch – Mission Genesis AI Manhattan Project initiative
Mission Genesis frames AI as critical infrastructure with national‑security urgency. The brief sets a 60‑day window to name priority challenges and pulls agencies and private partners into funded sprints.
Focus areas include advanced manufacturing, biotech, critical materials, nuclear fission, quantum energy, and semiconductors-AI becomes a force multiplier for speed and resilience.
Risks: compressed timelines can outpace safety and evaluation processes, and the geopolitical frame (U.S. vs. China) may accelerate vendor release cycles.
Product updates that matter now
OpenAI Shopping Research brings guided shopping into ChatGPT: product lists, specs, and quick comparisons inside chat. Right now it mirrors web search; value grows if it adds deals, coupons, or device/context tie‑ins.
Advanced voice in ChatGPT is now native to chat (running on GPT‑4o). It’s primarily a UX win for field sales, support, and accessibility rather than a reasoning upgrade.
On visuals, the Black Forest Labs FX 2 image model is strong, flexible, and can run locally via ComfyUI, offering enterprises a privacy‑focused alternative to closed systems.
Jobs and economics – what’s changing into 2026
Two big reads shape the outlook: MIT research estimating ~11.7% of U.S. jobs are replaceable with current AI under broad deployment (MIT), and McKinsey’s modeling that up to ~57% of hours could be automated in theory (McKinsey MGI).
Observed cuts are concentrated in routine knowledge roles-research, drafting, transcription, tagging, triage, and junior code review. The core throttle is integration into ERP/CRM/BI and compliance; as vendors ship embedded copilots and workflow actions, adoption accelerates.
Practical step: inventory task‑hours by ambiguity, risk, and unit cost; pilot objective tasks with low error cost; measure price per solution and rework; add governance early (data boundaries, human‑in‑the‑loop, audit trails).
Expert perspectives shaping expectations
The Ilya Sutskever interview highlights that scaling improves models, but AGI likely needs new ideas beyond pure scale. His note about safety clarifies “won’t destroy the world” rather than “no impact.”
Roman Yampolskiy argues that bounded, domain‑specific systems can deliver big productivity gains with lower existential risk (Yampolskiy paper).
That aligns with current ROI patterns: vertical copilots and agents win fast.
Buyer’s guide – choosing between Claude 4.5 Opus and Gemini 3 Pro
Choose Claude 4.5 Opus when your workflow is execution‑first: plan → call tools → parse errors → retry → PR. It shines on agentic tool‑use and tends to be token‑efficient on complex fixes (see Anthropic).
Choose Gemini 3 Pro (or evaluate GPT‑5.1) when breadth matters: cross‑domain law/biology/finance reasoning, long contexts, consumer flows. Lower per‑token rates help for high‑coverage tasks-see Vertex AI pricing.
Your evaluation checklist:
- Pick 5–10 real tasks you do weekly.
- Run both models, capture input/output tokens, first‑try success, retries, latency, and time to done.
- Test tool chains end‑to‑end (auth, rate limits, flaky APIs).
- Decide on price per solved task, not per‑million tokens; add compliance & data rules early.
Conclusion
The choice is fit, not brand. Claude 4.5 Opus is the steady hand for code and agents; Gemini 3 Pro is the wide‑angle planner for reasoning and consumer flows.
Measure AI model pricing per solution and token efficiency; re‑run bake‑offs every 8–12 weeks; and mix models where appropriate to cut cost and raise quality.
Simple start: bench 5–10 real tasks, log tokens/retries/latency/time to done, pick the model that clears your bar at the lowest price per solved task-and complement it with the other model where it shines.
FAQs
How do Claude 4.5 Opus vs Gemini 3 Pro benchmarks differ across coding and reasoning?
Opus leads on execution‑heavy code work and agentic tool chains. Gemini 3 Pro (and often GPT‑5.1) lead on cross‑domain reasoning tests like GPQA Diamond, MMMU/MMU, and MMLU. Pick for workload fit, not headline scores. (SWE‑bench)
What is the real cost once we factor token efficiency and retries?
Per‑million tokens is a weak proxy. If a model uses 70%+ fewer tokens and solves tasks in one shot, it can win even with a higher rate. Compute total cost per solved task, including retries and human rework. (See Anthropic.)
How does Mission Genesis affect the AI roadmap and risk posture?
Expect faster releases, larger compute budgets, tighter procurement, and a stronger U.S.–China competition frame-benefits in speed and funding, risks from safety lag. (White House brief)
Are near‑term layoffs likely in my function given the MIT/McKinsey numbers?
Risk is highest for routine knowledge tasks. MIT estimates ~11.7% of U.S. jobs replaceable under broad adoption; McKinsey models up to ~57% of hours automatable in theory. Integration speed controls near‑term pace. (MIT, McKinsey MGI)
What’s the practical value of the OpenAI Shopping Research feature today?
It’s a smoother way to scope options inside chat right now-mirrors web search. Value expands if it adds verified deals, coupons, or account/device context. (OpenAI blog)
Does voice in ChatGPT change capability or just UX?
Mostly UX. Native voice is hands‑free and fluid, boosting adoption. Reasoning is still tied to GPT‑4o quality. (OpenAI blog)
Can open models replace closed image tools for enterprises?
In some cases, yes. The Black Forest Labs FX 2 model is realistic and can run locally via ComfyUI, offering privacy and control advantages. (Black Forest Labs)
How often should I re‑run my model bake‑off?
Every 8–12 weeks. Vendors ship fast and small monthly lifts compound-keep the same task suite and metrics to compare apples to apples.
What guardrails should I set before scaling agents?
Define data boundaries, run red‑team prompts, require chain‑of‑thought only when needed, log tool calls, add human‑in‑the‑loop on high‑risk steps, and build an audit trail by default.
Should I mix models in one product?
Yes. Treat models like teammates: route execution‑heavy chains to a surgical executor and big‑picture planning to a wide‑angle planner to cut cost and raise quality.